SHA, c’est bien
Avant de plonger dans les détails des types d’objets git, je me dois d’expliquer l’une des propriétés majeures de l’outil.
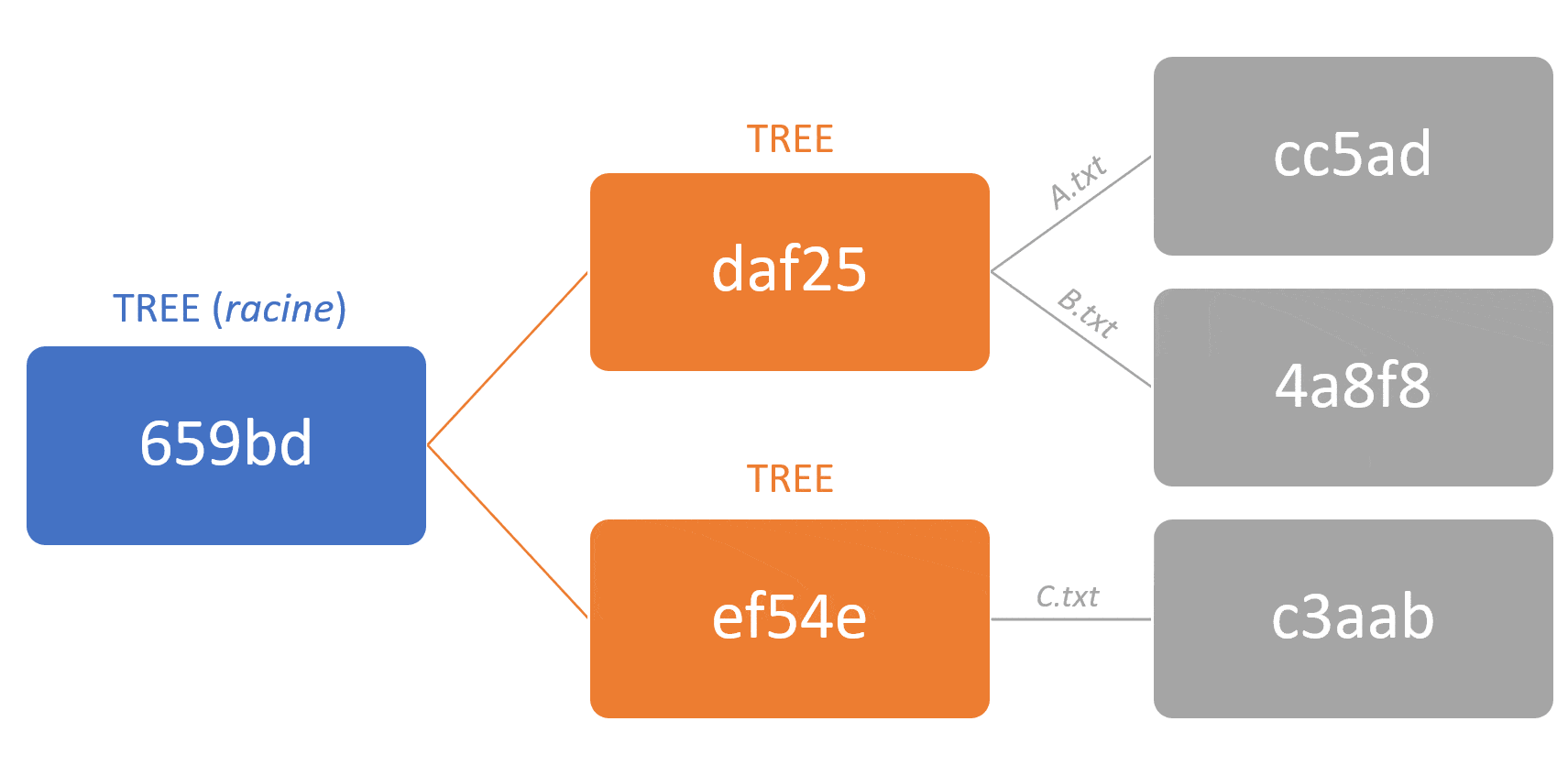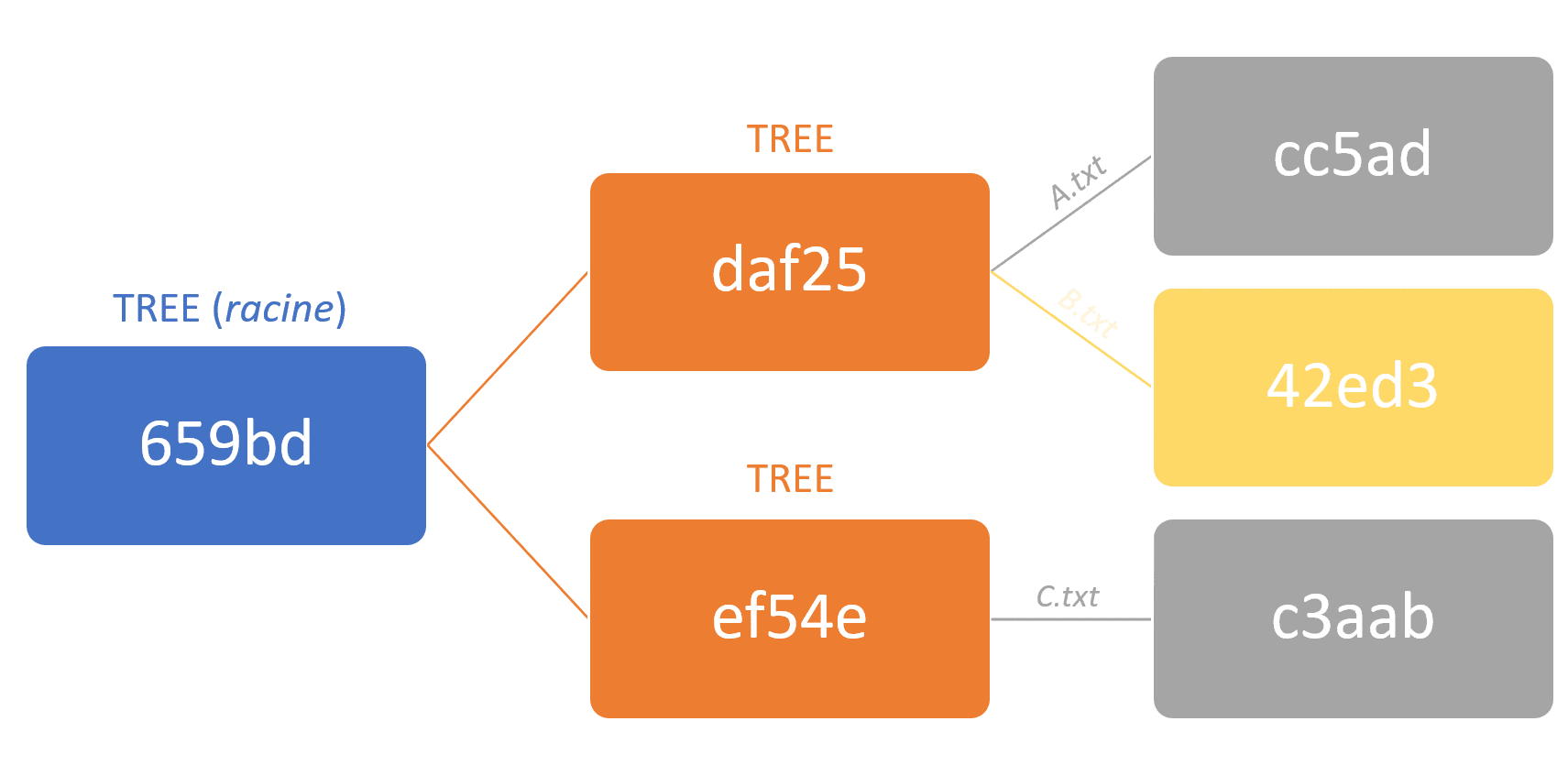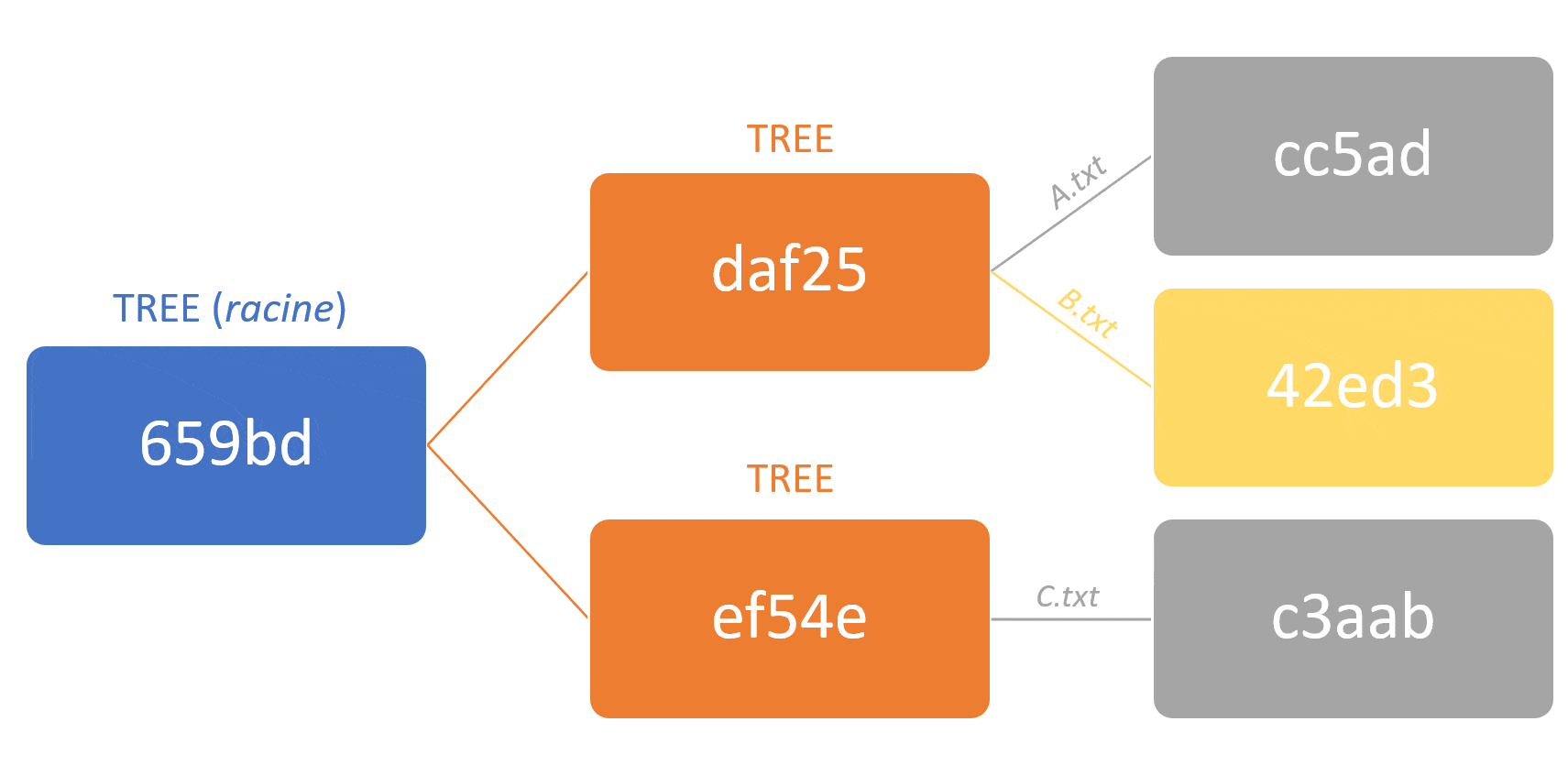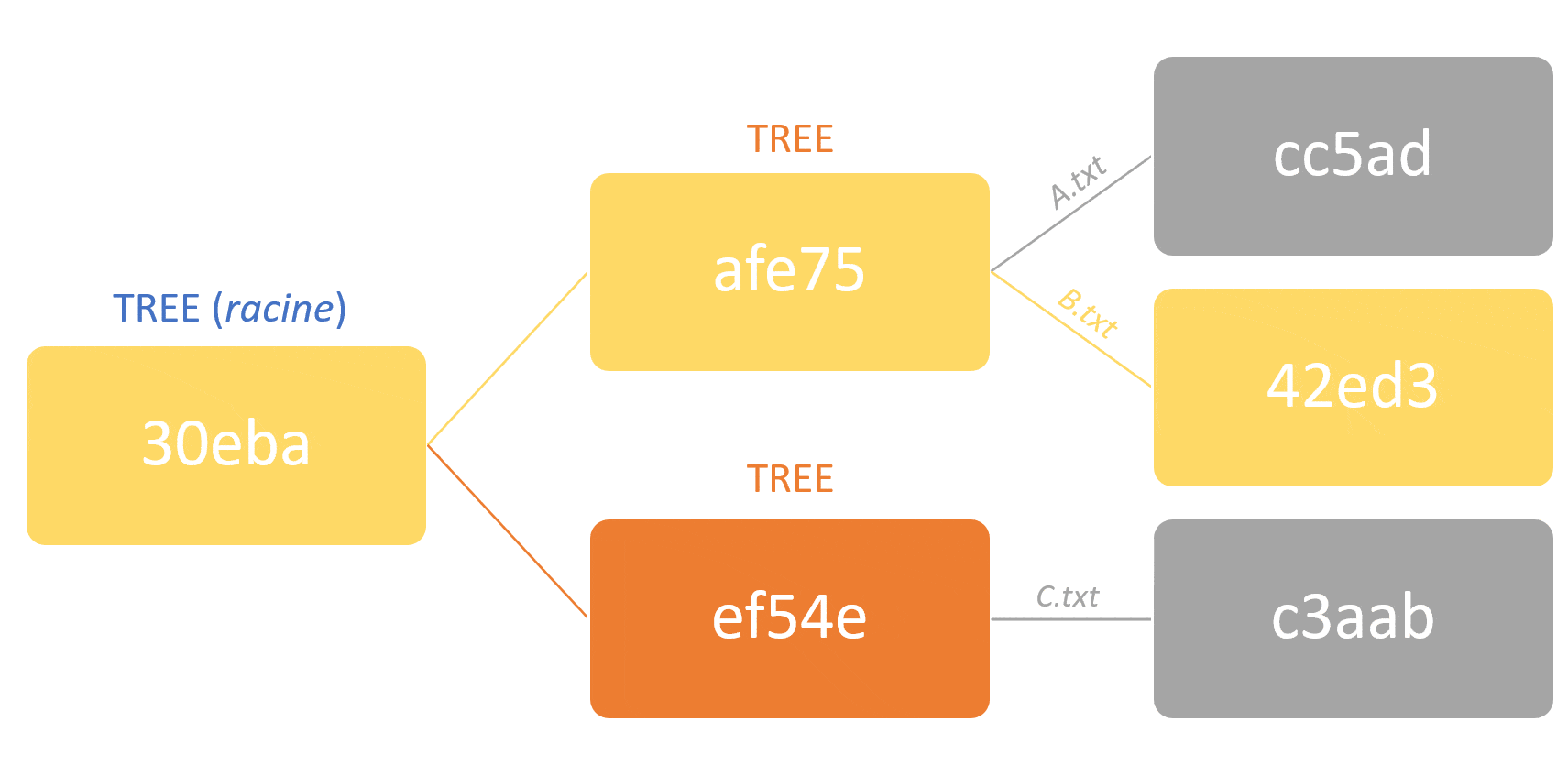
Le modèle Git est dit à contenu adressable (content-addressable in english). Cela veut dire que chaque objet est représentable via un identifiant unique calculé à partir du contenu binaire de l’objet, au lieu d’un identifiant arbitraire (comme un nom ou un ID incrémenté séquentiellement).
Cet identifiant unique est plus communément connu sous le nom hash.
Le hash est le résultat d’une fonction de hachage cryptographique. Voici les avantages d’une telle fonction pour adresser le contenu des données Git :
– Étant une somme de contrôle, le hash permet la vérification de l’intégrité du contenu
– La recherche d’objets en base est rapide
– Les objets peuvent être signés (avec par exemple une clé GPG)
Git utilise l’algorithme SHA-1, conçu par la NSA, pour calculer le hash de chaque objet.
Le résultat de cet algorithme dans Git est un hash de 160 bits qui représentent la concaténation :
– D’un en-tête, comprenant le type de l’objet, un espace, sa taille et un octet nul
– Du contenu du fichier en lui-même
Rien ne vaut un exemple pour illustrer ce fameux hash ! Cela nous permettra de voir une première commande peu utilisée de Git !