Add; Commit; Push; Branch; Merge… Ces termes sont utilisés quotidiennement par les utilisateurs de Git. Pourtant peu connaissent vraiment le fonctionnement interne de ce VCS (Version Control System).
Que se passe-t-il lorsque l’on réalise un commit ? Comment Git versionne et sauvegarde les données de votre projet ?
Le but de cet article est de répondre à ces questions et de présenter de manière concise les entrailles de cet outil tant apprécié des développeurs.
Mais d’abord, faisons un petit cours accéléré de ce qu’est Git pour que tous les lecteurs, utilisateurs de Git ou non, soit sur un pied d’égalité (tout du moins sur les notions théoriques).
Rappel de ce qu’est Git
Git a été créé en 2005 par Linus Torvald, mais c’est grâce à l’avènement de Github en 2008 et à son gain rapide en popularité que cet outil est devenu le VCS le plus utilisé au monde (plus de 73 millions d’utilisateurs sur github en 2021).
Diagramme représentant le pourcentage de répertoire des différents VCS Source
Euh… VCS ? Kézako ?
Un VCS, pour Version Control System (Système de Contrôle de révisions dans la langue de Molière), est un logiciel qui va permettre de tracer les modifications des fichiers de votre projet au fil du temps.
Ainsi, avec un outil tel que Git, vous pouvez, entre autres : • Enregistrer plusieurs versions de votre projet • Remonter dans le temps et revenir à des versions antécédentes de vos fichiers • Paralléliser les développements avec les branches
Remarque : Git seul n’est pas un outil de backup de votre projet ! En effet, il faut héberger votre projet sur un serveur distant ou utiliser les différentes solutions SAAS d’hébergement tel que Github, Gitlab ou Bitbucket.
De plus, il faut imaginer Git comme une base de données stockant le contenu des fichiers de votre projet. C’est ce que l’on appelle le répertoire Git (ou repo pour les intimes). Plus précisément, le répertoire Git contient les différentes versions (commits) du projet au fil du temps. Chaque commit représente donc l’état de votre répertoire de travail au moment où il a été enregistré. Par ailleurs, chaque commit contient un lien vers le commit précédent (appelé commit parent). C’est pourquoi l’on représente l’historique Git sous forme d’un arbre de commits :
Schéma représentant un arbre simple, où chaque lettre représente un commit
L’allégorie de l’arbre est encore plus pertinente car comme la plante, l’historique Git est composé de branches. En effet, ces dernières vont permettre le travail en parallèle ainsi que la gestion de plusieurs versions concurrentes du projet :
Schéma représentant les branches Git
Bon, revenons à nos moutons, je ne voudrais pas ennuyer ceux qui connaissent déjà ces notions de base ! Après ce petit rappel de ce qu’est Git, il est grand temps d’aller fouiller et voir ce que la bête a sous le capot !
SHA, c’est bien
Avant de plonger dans les détails des types d’objets git, je me dois d’expliquer l’une des propriétés majeures de l’outil.
Le modèle Git est dit à contenu adressable (content-addressable in english). Cela veut dire que chaque objet est représentable via un identifiant unique calculé à partir du contenu binaire de l’objet, au lieu d’un identifiant arbitraire (comme un nom ou un ID incrémenté séquentiellement).
Cet identifiant unique est plus communément connu sous le nom hash.
Le hash est le résultat d’une fonction de hachage cryptographique. Voici les avantages d’une telle fonction pour adresser le contenu des données Git :
– Étant une somme de contrôle, le hash permet la vérification de l’intégrité du contenu – La recherche d’objets en base est rapide – Les objets peuvent être signés (avec par exemple une clé GPG)
Git utilise l’algorithme SHA-1, conçu par la NSA, pour calculer le hash de chaque objet. Le résultat de cet algorithme dans Git est un hash de 160 bits qui représentent la concaténation :
– D’un en-tête, comprenant le type de l’objet, un espace, sa taille et un octet nul – Du contenu du fichier en lui-même
Rien ne vaut un exemple pour illustrer ce fameux hash ! Cela nous permettra de voir une première commande peu utilisée de Git !
Prenons ce beau logo de Novencia :
La commande hash-object va nous permettre de récupérer le hash SHA-1 de cette image :
Cet hash est utilisé en paramètre de nombreuses autres commandes Git. Bien évidemment, vous n’êtes pas obligé d’indiquer l’entièreté des quarante caractères. En effet, Git est assez intelligent pour déterminer de quel objet vous parlez avec un hash partiel d’au moins 4 caractères. Ici, ce serait 3e4B. Pour les répertoires plus larges, il faudra en indiquer plus pour que l’outil puisse distinguer le hash voulu.
Il faut savoir que l’algorithme SHA-1 n’est pas parfait. Des défauts de collisions ont été découverts ces dernières années (dont l’attaque SHAttered en 2017). Cela a poussé les mainteneurs Git à utiliser une version renforcée du SHA-1 depuis la version 2.13.0. De plus, depuis 2018 un effort est fait pour transitionner et passer au SHA-256, plus robuste que le SHA-1.
Aujourd’hui, il est possible d’utiliser le SHA-256 comme fonction de hachage, mais la fonctionnalité est encore au stade expérimental et les hébergeurs cloud (dont Github) ne le supportent pas encore.
Git Data Model
Je n’ai pas arrêté de parler d’objets, et vous vous demandez sûrement de quoi il s’agit ! Le prochain passage va vous intéresser 😊.
Pour comprendre la base de données interne de Git, il faut l’imaginer comme un système de fichiers UNIX (simplifié) qui va représenter l’état de notre projet à un temps donné.
Partons d’un exemple de répertoire git simple pour illustrer ça :
Ce repo contient uniquement un fichier fun_facts.txt comportant des faits intéressants, comme « Une journée sur Vénus est plus longue qu’une année ».
Cet exemple va nous permettre de découvrir les 3 types d’objets immutables de Git :
Le blob
Lorsque vous enregistrez un fichier sur un périphérique de stockage (disque dur, SSD, flash, …), vous sauvegardez non seulement le contenu de ce dernier, mais aussi des métadonnées permettant de mieux l’identifier. En plus du contenu, il y aura donc le nom, la date de création/de modification et le propriétaire (pour n’en citer que quelques-uns) qui seront conservés lors de l’enregistrement.
Git au contraire, n’a que faire de ces informations supplémentaires. En effet, tout ce qui l’intéresse est le contenu binaire du fichier. C’est ce que l’on appelle le blob (Binary Large Object).
Dans notre exemple précédent, le seul blob de notre projet correspond à fun_facts.txt :
Il est vraiment important de comprendre que le nom du fichier importe peu pour Git. Seul le contenu binaire permet de définir un fichier.
Ainsi, deux fichiers ayant des noms différents mais le même contenu seront représentés par un unique blob dans le répertoire Git.
Le tree
Dans Git, un répertoire sera modélisé par l’objet tree. De la même manière qu’un dossier sur votre machine peut contenir aussi bien des fichiers que d’autres sous-dossiers, le tree va référencer le hash des blobs et d’autres objets tree ainsi que leur nom correspondant. C’est donc dans le tree que l’on retrouve l’information du nom de nos fichiers.
Il n’y a pas de sous-dossier dans notre exemple de repo. En revanche, il existe tout de même un tree, qui correspond au dossier racine du projet :
Le commit
Cet objet est le plus connu, le commit. Ce dernier représente l’état de votre projet à un instant t. Techniquement, il est composé :
– D’un pointeur vers l’arbre racine du projet et d’un autre vers au moins un commit parent (possiblement plusieurs s’il s’agit d’un commit de merge, ou un pointeur NULL si c’est le premier commit du repo) – D’un auteur, qui représente la personne ayant réalisé les modifications – D’un committeur*, i.e. la personne ayant effectivement appliqué le commit dans le repo – D’un message de commit
Dans la plupart des cas, l’auteur et le committeur sont la même personne. Ils peuvent différer lorsque l’on vient réécrire un commit ou lorsque quelqu’un d’autre que l’auteur du code applique le commit.
Nous n’avons qu’un commit dans notre projet. Le schéma du commit devient donc :
Le tag annoté
Il existe un dernier type d’objet dans Git, le tag annoté, que l’on va décrire succinctement. Un tag est un moyen de nommer un commit autrement que par son SHA.
Il existe deux tags dans Git :
Le tag léger, qui n’est pas un objet dans la base de données git mais simplement un fichier texte pointant sur un commit. Et d’un autre se nommant, le tag annoté, qui lui est un objet à part dans la base de données Git, avec son propre hash, le nom du taggeur, la date et un message de tag.
Les objets Git en pratique
Les schémas, c’est bien sympa, mais si vous voulez pratiquer, sachez qu’il est très facile de parcourir le contenu de ces objets en ligne de commande.
La commande cat-file -p <object> permet d’afficher le contenu d’un objet Git. Si on met en pratique pour notre projet, cela donne :
Si maintenant on réexécute cette commande pour l’arbre associé à ce commit :
En effet, on remarque que notre tree ne contient qu’un blob appelé fun_facts.txt.
Si on regarde le contenu de ce dernier :
On retrouve le contenu de notre fichier !
Ce qu’il faut retenir
Schéma représentant l’ensemble des types d’objets et références de git
La base de données Git ne contient uniquement que les quatre types d’objets vu précédemment. Toutes les autres notions que vous connaissez ne sont que des références à des commits. Ainsi, une branche ou un tag ne sont que des fichiers textes contenant le hash du commit associé.
Le pointeur HEAD est un peu différent car il s’agit d’une référence symbolique. En effet, cela veut dire qu’en temps normal, il pointe non pas sur un commit mais sur une branche. À noter que s’il ne pointe pas sur une branche, on dit qu’il est dans un état détaché.
Ces fichiers références sont stockés dans le dossier .git/refs. Regardons le fichier HEAD de notre branche principale :
Nous voyons bien que le fichier de la branche master n’est composé que d’une ligne contenant le hash SHA-1 complet du dernier commit de la branche.
Merkle Tree
Comme expliqué au début, les objets Git sont adressables par leurs contenus. Le hash d’un commit est calculé (en plus des métadonnées) à partir du hash de l’arbre racine (tree) de votre projet. Celui-ci est généré à partir des hash de ses nœuds fils, qui peuvent être d’autres trees ou des blobs.
Ce type de structure, où l’identifiant de chaque nœud est calculé à partir des hash des nœuds fils, est appelé un arbre de Merkle (d’après son inventeur, Ralphe Merkle, en 1979). Pour votre information, sachez que Bitcoin implémente aussi une version de l’arbre de Merkle pour la gestion des transactions du blockchain.
Par ailleurs, puisque chaque commit à la référence de son/ses commits parents, il nous est possible de traverser à partir d’un commit tous ses parents dans un sens sans avoir de chaîne commençant ou finissant par le même objet. C’est ce que l’on appelle un graphe orienté acyclique (Directed Acyclic Graph).
Concrètement, ce sont ces deux principes qui permettent à Git d’être :
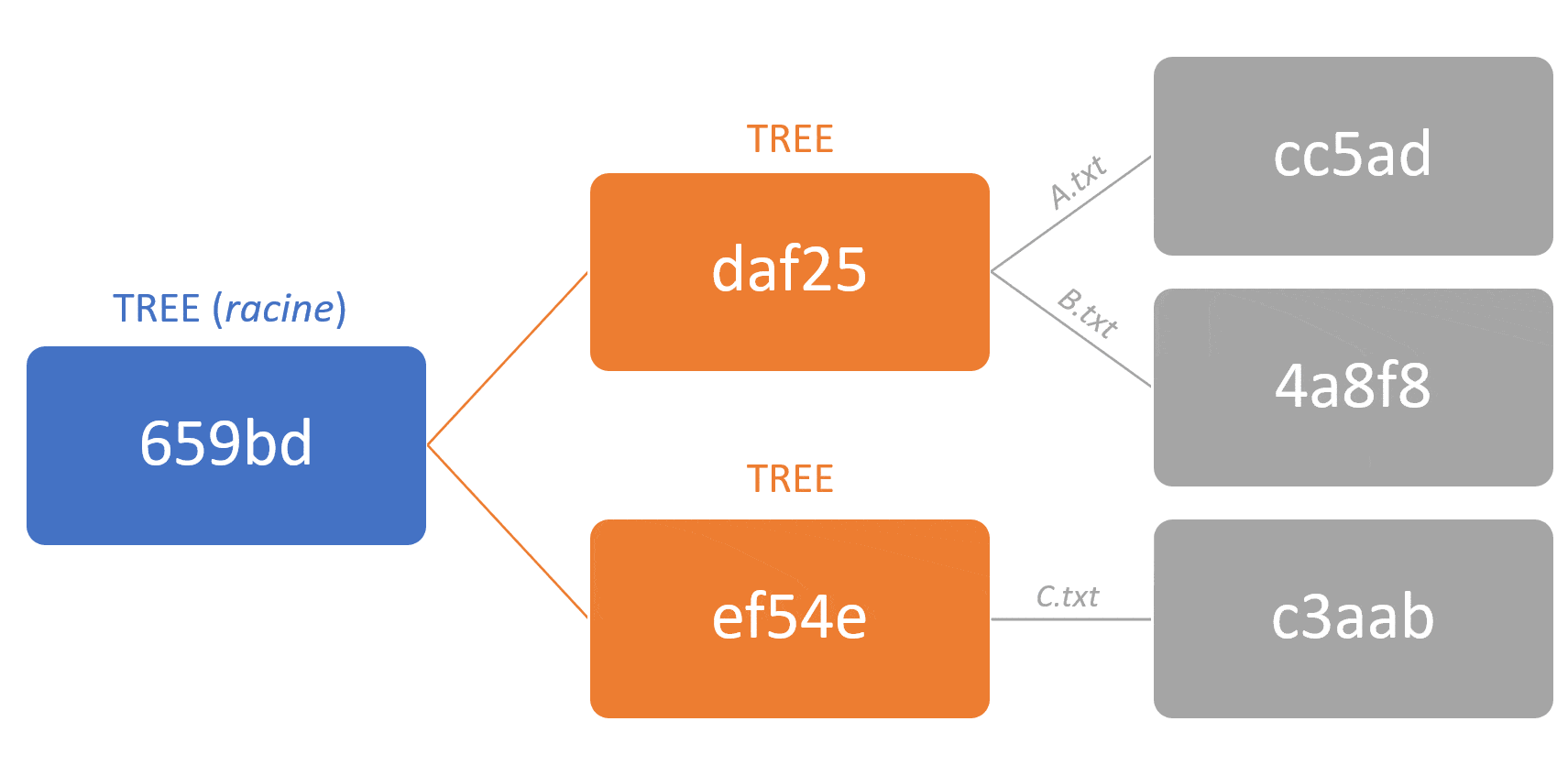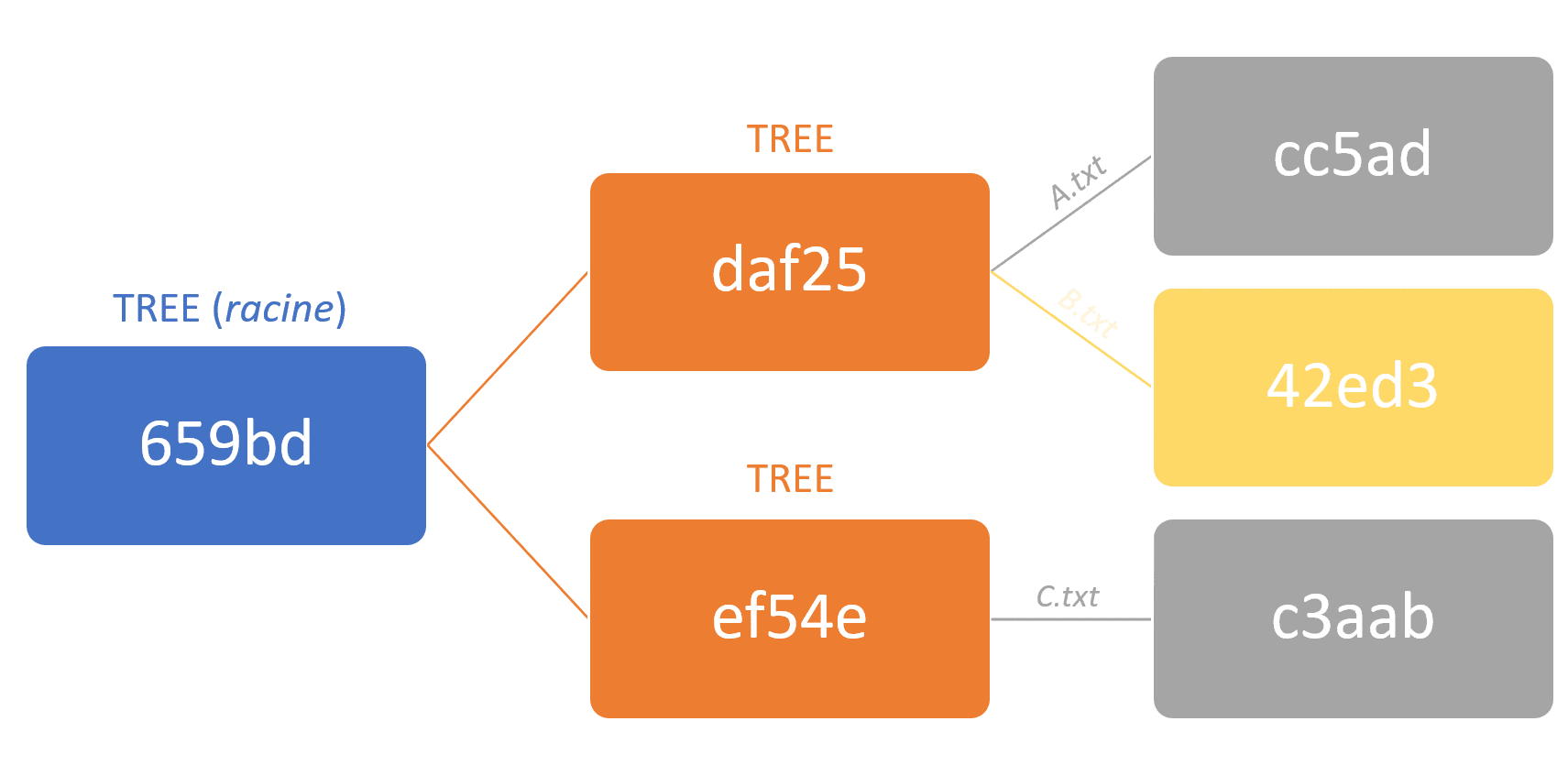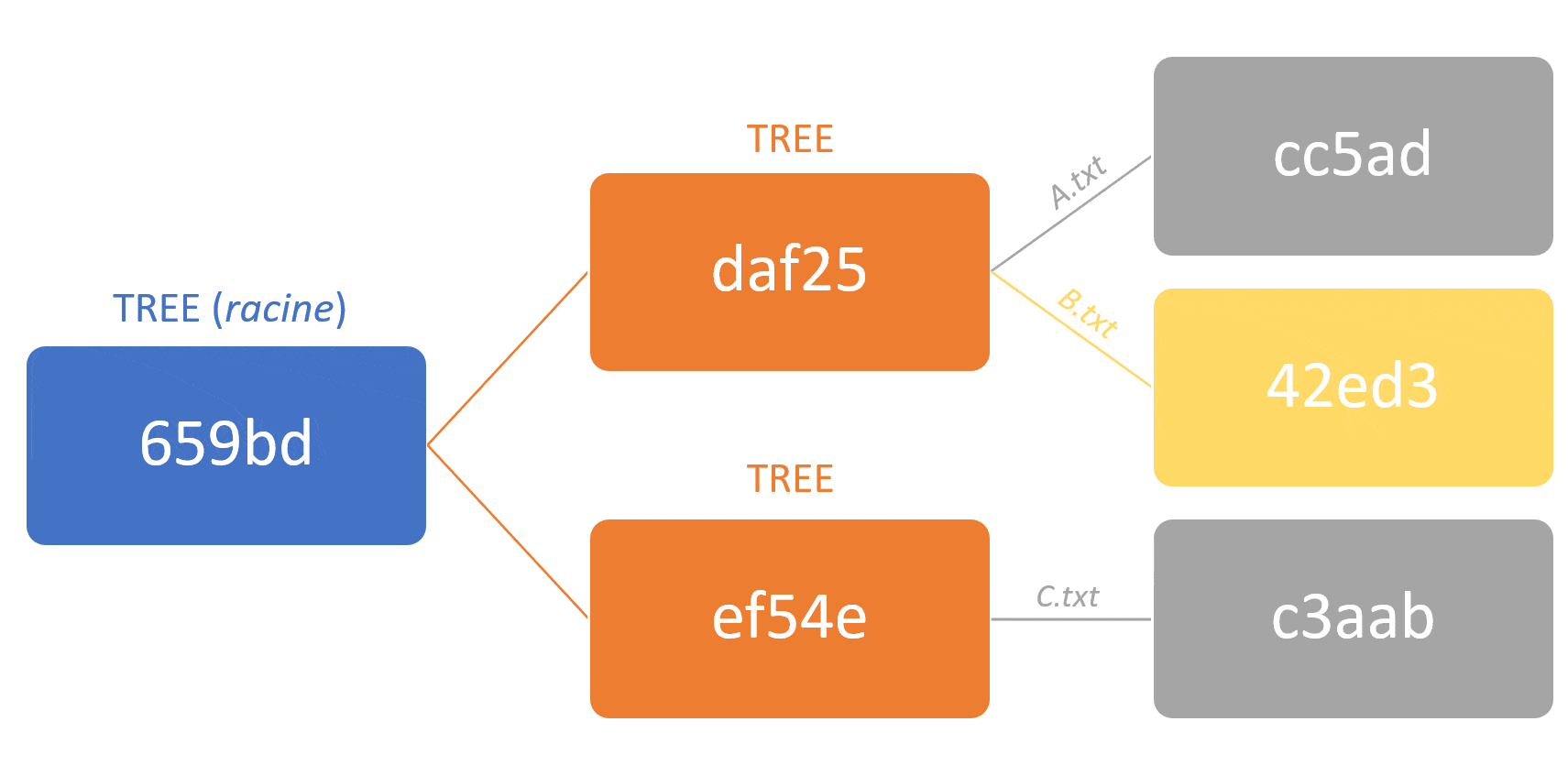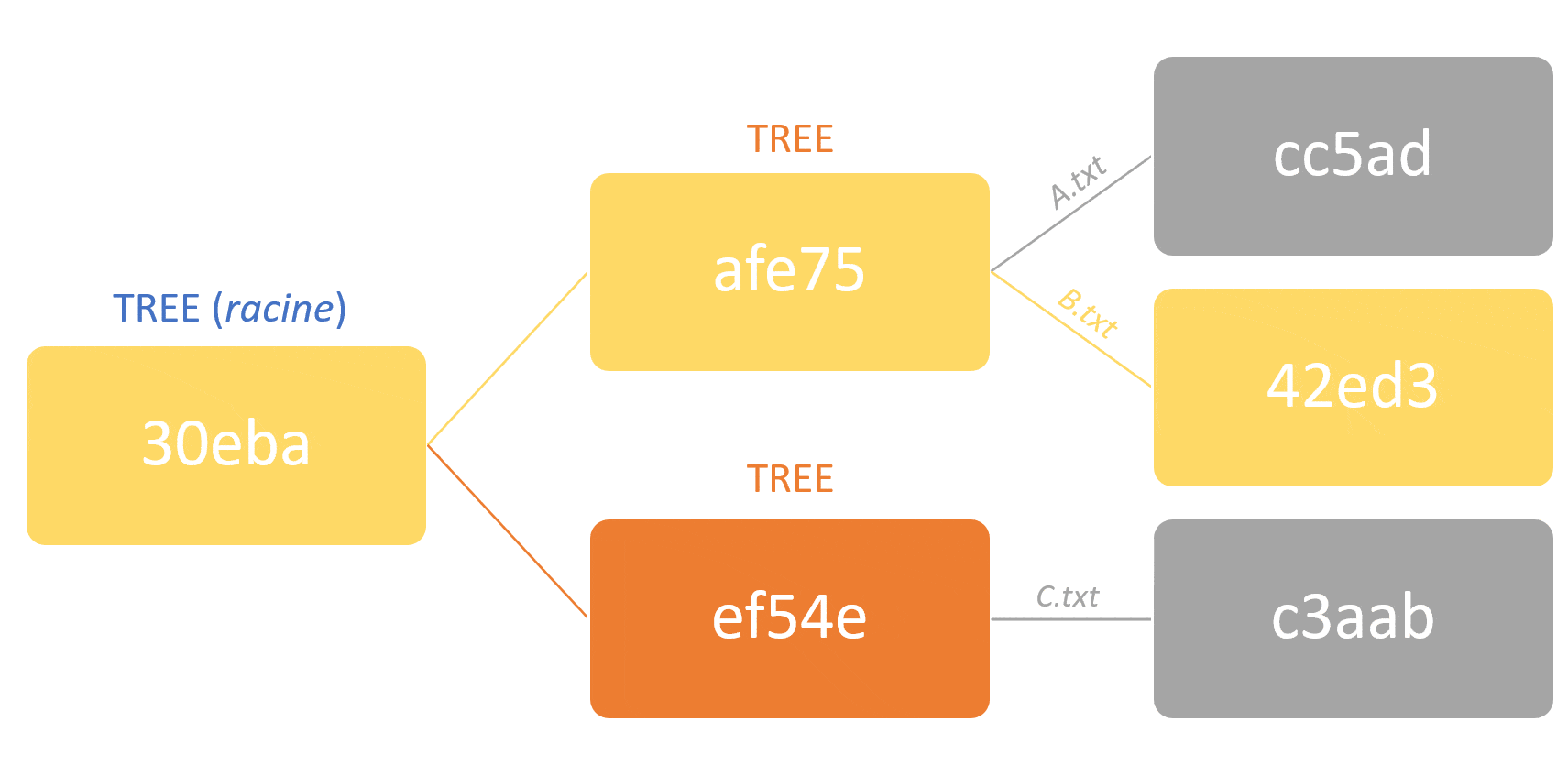
– Résistant à la corruption/falsification des données : Modifier un fichier entraîne la modification de chaque tree qui le référence, ce qui à leur tour entraînent le changement de chaque tree qui les référence, et ainsi de suite, jusqu’à arriver au commit.
Schéma montrant que la modification d’un fichier entraîne la modification de tous les parents
– Performant : Lors des opérations réalisées sur le répertoire distant (push, pull), seuls les objets qui ont été réellement modifiés sont transférés sur le réseau. Ainsi, Git va comparer les arbres racines du dernier commit (local vs distant). S’ils sont différents, il va comparer récursivement leurs sous-objets (tree ou blob) pour déterminer et envoyer uniquement les objets qui ont été modifiés.
Cela signifie aussi qu’un commit contient tout votre projet, et non seulement les fichiers qui ont été modifiés lors de ce commit !
Conclusion
Nous avons découvert dans cet article le modèle de données interne de Git, qui utilise le hash comme somme de contrôle pour gérer l’intégrité de tous ses objets. J’espère que vous comprenez mieux comment Git gère vos projets et vos commits. Dans tous les cas, je vous invite à refaire les quelques commandes vu tout au long pour mieux vous imprégner de ces notions.
Amirali Ghazi
En réagissant à cet article, vous nous permettez d'affiner les contenus que nous publions ici !
Interesting(2)
Awesome(0)
Useful(0)
Boring(0)
Sucks(0)
Si cet article vous a plu, n’hésitez pas à le partager via