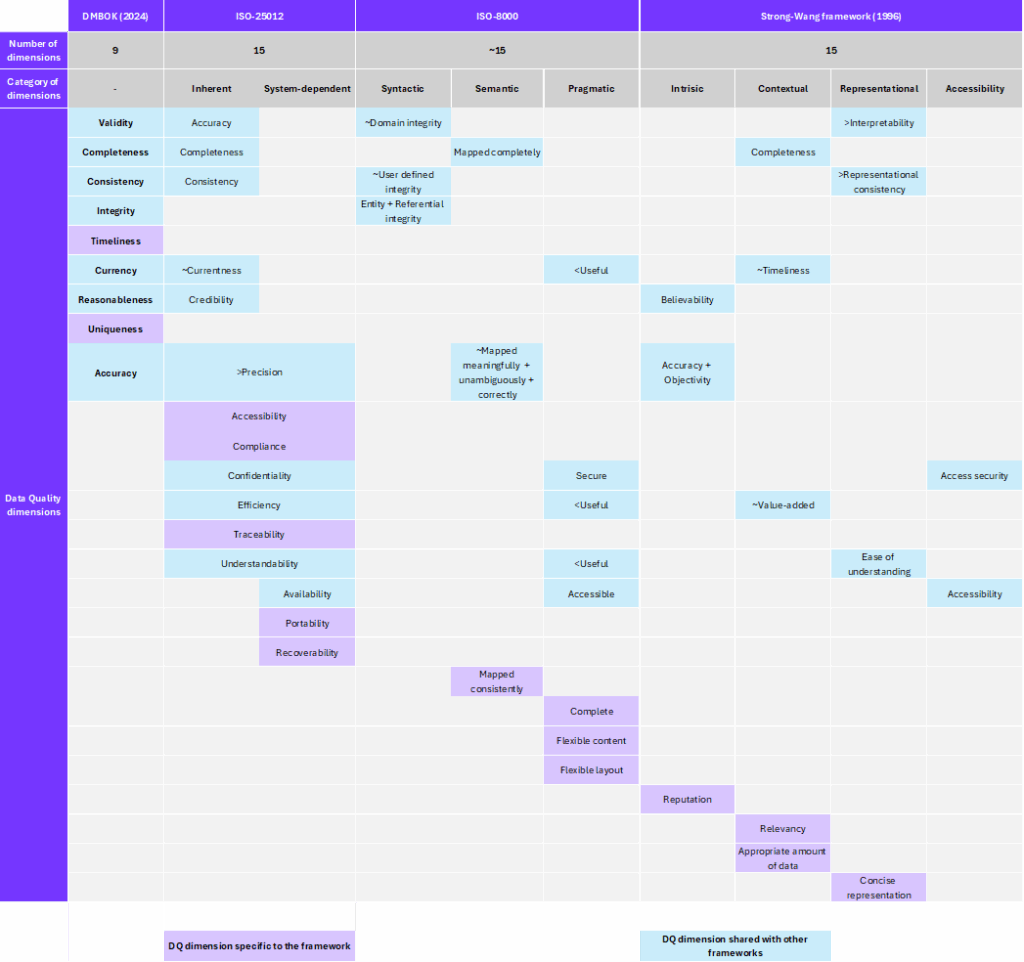




La solution Data Quality AI novencia  vous permet de mesurer la qualité de données sur l’ensemble de ces dimensions en nécessitant le moins possible de ces éléments. En effet, à travers son utilisation de l’IA, et en partant uniquement de vos données, la solution novencia est notamment capable de déduire nativement :
vous permet de mesurer la qualité de données sur l’ensemble de ces dimensions en nécessitant le moins possible de ces éléments. En effet, à travers son utilisation de l’IA, et en partant uniquement de vos données, la solution novencia est notamment capable de déduire nativement :
- Le format et le type de données attendu
- Les relations attendues entre plusieurs champs
- Les exigences de complétion des champs
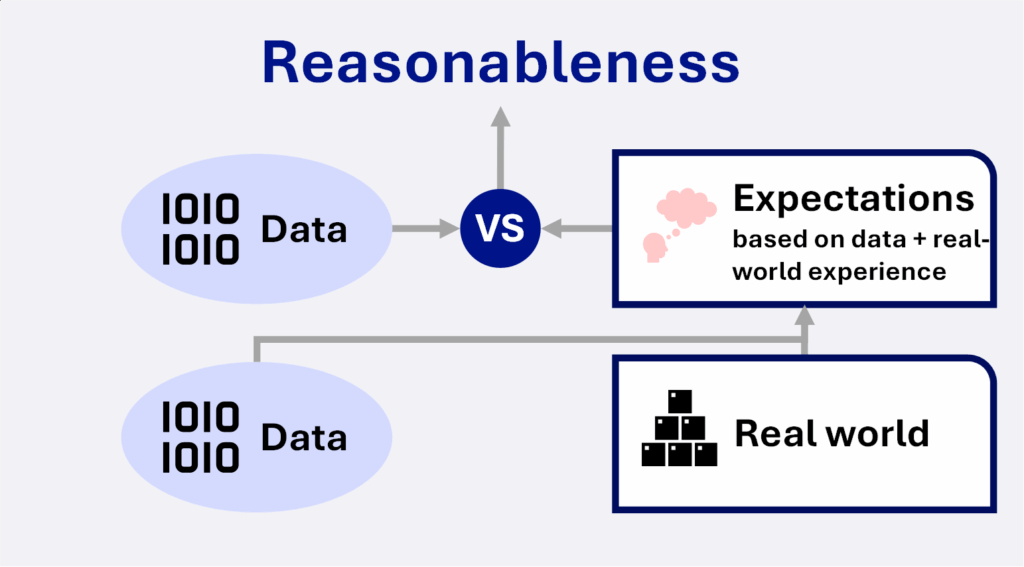
- Les attentes sur les valeurs d’un champ
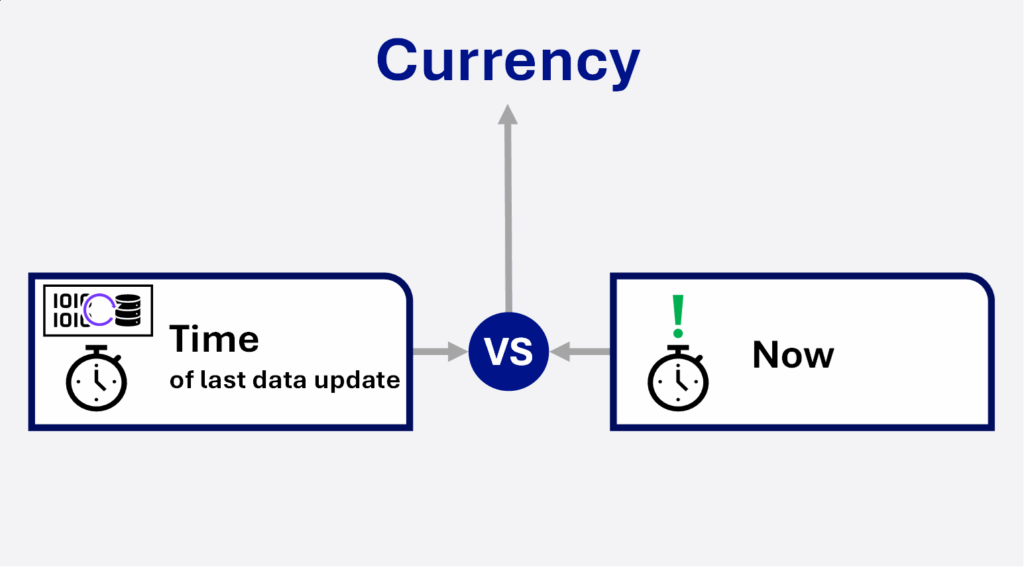
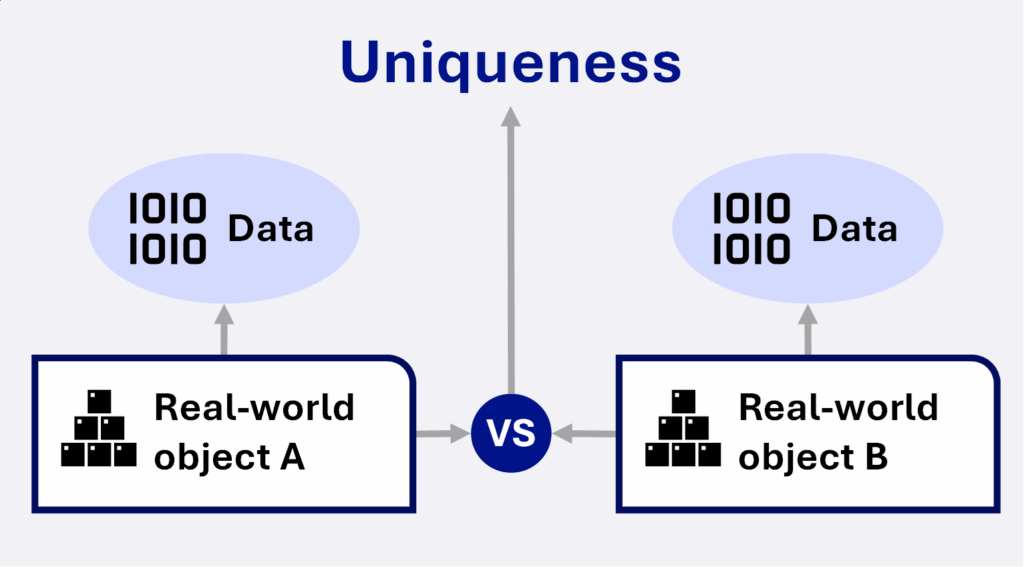
Certains éléments ne sont pas directement déduisibles de la donnée elle-même (comme les dates de collecte / de mise à jour ou bien les objets du monde réel). Mais si ces élements sont fournis par ailleurs (ex : mesure directe via objet connecté), la solution Data Quality AI novencia peut tout à fait être configurée pour les prendre en compte et ainsi donner une vision complète de la qualité de vos données.