

Au cours des 10 dernières années, nous avons assisté à l’augmentation des projets de Machine Learning au sein de tous les types d’entreprise quel que soit le secteur d’activité. Un essor poussé par le recueil et l’utilisation de plus en plus massive des données. Cependant, malgré l’avancée technologique, les équipes de Data Science (DS) sont confrontées à de plus en plus de pression pour livrer des produits devant être toujours plus intelligents et devant être utilisés en toute autonomie.
Cela implique des ressources qui travaillent simultanément sur un même environnement technique et sur un même objectif : accélérer la mise à disposition de la donnée et réduire le temps nécessaire pour la mise en production.
Tous ces changements nécessitent donc de trouver des solutions et outils à des problèmes récurrents dans la mise en production de modèles au sein des organisations. C’est là que vont entrer en jeu ce qu’on appelle les features store.
Qu’est-ce qu’un feature store ?
Le feature store est un service qui ingère de gros volumes de données, calcule des features et les stocke. Cela permet en matière d’apprentissage automatique d’aller plus vite en facilitant l’accès à la donnée.
Les features stores ont commencé à être utilisées dans la deuxième partie des années 2010, mis en place chez Uber à travers Michalengo, plateforme de ML capable aujourd’hui de gérer plus de 10 000 features au sein de l’entreprise. Depuis, d’autres géants de la tech ont adopté l’utilisation des features stores : Airbnb, Netflix, Pinterest, Amazon…
Hors Ligne et En ligne : une double utilisation possible pour les features store
Offline Features : certaines features sont calculées dans le cadre d’un travail par batch. Prenons l’exemple de dépenses mensuelles moyennes qui seront ensuite utilisées dans un deuxième temps pour être intégrées dans un modèle. Elles sont donc principalement utilisées par des processus hors-ligne. Compte tenu de leur nature, la création de ces types de fonctionnalités peut prendre du temps. Habituellement, les fonctionnalités hors ligne sont calculées via des Framework tels que Spark ou en exécutant simplement des requêtes SQL sur une base de données choisie, puis en utilisant un processus d’inférence par lot.
Online Features : celles-ci sont plus complexes, car elles doivent être calculées très rapidement, les résultats doivent souvent être envoyés avec un temps de latence rapide.
Prenons l’exemple d’un modèle qui tourne en production pour la détection de fraude en temps réel, le résultat du score doit être fourni rapidement. Dans ce cas, le pipeline est construit en calculant la moyenne et l’écart-type sur une fenêtre glissante en temps réel. Ces calculs sont beaucoup plus difficiles et nécessitent un calcul rapide ainsi qu’un accès rapide aux données. Les données peuvent être stockées en mémoire ou dans une base de données.
Voici une illustration issue du blog technique d’Uber qui illustre le fonctionnement et la différence des features online & offline.
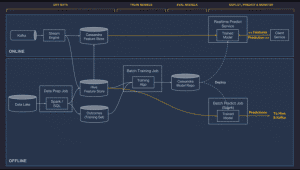

Quels sont les avantages de l’utilisation des features stores ?
-
Un développement plus rapide
Idéalement, les data scientists doivent se concentrer sur la construction des modèles. Toutefois, ils passent souvent une majorité du temps du projet sur des tâches de data engineering, de recherches de la donnée etc… Certaines features sont coûteuses à calculer et nécessitent des agrégations supplémentaires. Les features stores permettent de centraliser les features déjà développées, qui peuvent être réutilisées plus rapidement.
Les fonctionnalités en ligne et hors ligne ont des caractéristiques différentes. Sous le capot, les fonctionnalités hors ligne sont principalement construites sur des frameworks tels que spark ou SQL, où les fonctionnalités réelles sont stockées dans une base de données ou dans des fichiers Parquet. Alors que les fonctionnalités en ligne peuvent nécessiter un accès aux données à l’aide d’API pour les moteurs de streaming tels que Kafka, Kinesis ou des bases de données clé-valeur en mémoire telles que Redis ou Cassandra.
L’utilisation de features stores permet d’abstraire cette couche, de sorte que lorsqu’un data scientist recherche une fonctionnalité, au lieu d’écrire un code d’ingénierie, il peut utiliser une simple API pour récupérer les données dont il a besoin.
-
Un déploiement fluide de modèles en production
La mise en production rencontre plusieurs obstacles. Par exemple, l’entrainement des modèles qui se fait sur des environnements différents de ceux en production. Par conséquent, l’utilisation d’un ensemble de features cohérentes entre la couche de formation et la couche de service permet un processus de déploiement plus fluide, et garanti que le modèle formé reflète la façon dont les choses fonctionneraient en production.
-
Des modèles plus précis
En plus des features réelles, le features store conserve des métadonnées supplémentaires pour chaque feature. Par exemple, une métrique qui montre l’impact de la feature sur le modèle auquel elle est associée.
Ces informations peuvent être d’une aide précieuse pour les data scientists lorsqu’ils sélectionnent des features pour un nouveau modèle, en leur permettant de se concentrer sur celles qui ont eu un meilleur impact sur des modèles existants similaires.
-
Une meilleure collaboration
Il y a une augmentation exponentielle des projets qui implique l’utilisation d’apprentissage automatique, de sorte que le nombre de features augmente également. Cela réduit la capacité des équipes à avoir une vue d’ensemble des features disponibles. Au lieu de développer en silos, le feature store permet de partager à toute l’entreprise les features utilisées, mais également les métadonnées de ces dernières.
-
Conformité à la réglementation & suivi des algorithmes développés
Afin de répondre aux différentes réglementations en vigueur ou en cours d’implémentation (en particulier dans les secteurs tels que la santé, les services financiers et la sécurité), il est important de suivre le lineage des algorithmes développés. Pour y parvenir, il faut avoir une visibilité sur le flux de données global de bout en bout afin de mieux comprendre comment le modèle génère ses résultats. L’intérêt d’un feature store est justement de conserver l’historique des données utilisées.
En résumé, ils permettent de mobiliser moins de ressources au sein des différentes directions concernées par les projets de Data Science utilisant ces nouvelles plateformes. Ces dernières peuvent réutiliser des features déjà existantes. De plus, les features stores permettent de passer en production plus rapidement tout en assurant une consistance et une standardisation des différents modèles.
Les features stores et les MLOps
On ne peut pas parler de features store sans évoquer le processus global dont ils font partie. Pour rappeler rapidement, le MLOps, est un ensemble de pratiques qui vise à déployer et à maintenir des modèles de machine learning en production de manière fiable et efficace. C’est une extension du DevOps dont l’idée est d’appliquer les principes DevOps aux pipelines de machine learning (ML). Le développement d’un pipeline de ML est différent du développement d’un logiciel, principalement en raison de l’aspect des données. La qualité du modèle n’est pas seulement basée sur la qualité du code. Elle repose également sur la qualité des données c’est-à-dire les features qui sont utilisées pour exécuter le modèle.
D’après le retour d’équipe engineering de Airbnb, les data scientists passent 60 à 80% de leur temps à la création, à la formation, et au test des données. Les magasins de caractéristiques permettent aux spécialistes des données de réutiliser les features au lieu de les reconstruire encore et encore pour différents modèles. Ils permettent donc d’automatiser ce processus et peuvent être déclenchés par des modifications du code poussées vers Git ou par l’arrivée de nouvelles données. Ce feature engineering automatisé est un élément important du MLOps.
Les features stores au service de la maximisation de la monétisation
Le passage vers des projets pensés dès le début pour être industrialisés, augmente le coût initial. De ce fait, les équipes data sont aujourd’hui vues comme des centres qui génèrent du profit. Ainsi, même si votre organisation n’y pense pas encore, la capacité des features store à définir et à stocker de grandes quantités de données, y compris complexes, représente une opportunité potentiellement lucrative pour les équipes Data et l’organisation au sens large.
En effet, disposer dès maintenant d’une stratégie efficace de collecte de données, avec une feuille de route pour la monétisation, contribuera non seulement à justifier l’investissement dans votre feature store, mais permettra également à l’organisation de se développer par le biais de la revente de données.
En conclusion, les data features store sont un atout si votre organisation développe et maintient un nombre de projets importants. Ils s’intègrent à une plateforme data existante et vous permettent de faire gagner du temps à vos équipes sur la préparation et l’application des features sur des projets Data.
Maya AZOURI, Consultante Data




